

采/访/实/录
INTERVIEW RECORD
Q1
什么是数据库类文章?
可持续资源管理的研究依赖于描述技术、社会、经济和环境系统中各种各样的数据。这些数据对于了解资源系统面临的挑战和制定资源可持续性解决方案至关重要。更重要的是,许多数据不仅适用于单一研究,而且对其他研究也很有用。因此,《Data in brief》和《Resources, Conservation & Recycling》等期刊都发表数据库类型的文章,鼓励与更广泛的研究团体分享这些关键数据,以实现更广泛的应用。
Q2
你们发布的是一个什么样的数据库?
Substance flow data of Chinese phosphorus cycle from 1949to2018提供了一个1949~2018年中国磷循环物质流数据,它包含了825个磷流在自然过程和人为过程之间转换的年度数据。数据采用以物质平衡为原理的物质流分析法计算。原始数据、计算公式以及不确定性分析也包含在数据库中。利用这些数据,可以分析磷在水-能源-粮食安全关系中的作用,也可用于辅助其他方法的使用。
Q3
这样的数据在之前的研究性文章中没有发布过么?
中国磷循环的物质流数据框架经过不同研究者的共同努力逐步完善,但随着社会经济发展,新的磷流正在产生,需要不断优化这一框架。本数据库有以下亮点,1)在时间尺度上涵盖了1949~2018年70年的数据;2)粮食损失和浪费、生物乙醇等被纳入计算框架;3)优化了某些子过程,比如畜禽养殖、肉类屠宰、肉类加工的边界得到规范;4)细化了磷流,使得有价值的825条数据得到更加透明的展示;5)对磷矿石库存、水产养殖废水沉积物等进行了识别。
Q4
如何使用你们的数据库呢?
本数据库发表在下述期刊上:
《Resources, Conservation & Recycling》
可以通过以下链接进入数据库网址,并阅读此数据库的使用方法。
https://doi.org/10.1016/j.resconrec.2023.107193
这里也简单介绍数据库的使用:
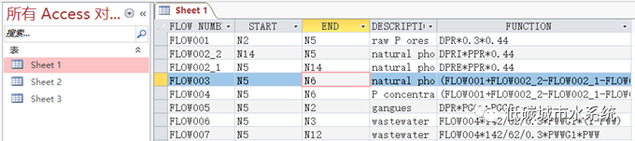
数据库共分为两部分,第一部分为一个名为《Chinese P cycle.accdb》的数据库文件,请使用Microsoft Access打开;第二部分是一个名为《README.doc》的文件,它对计算过程和关键数据结果进行了展示。
《Chinese P cycle.accdb》包含3个Sheet,Sheet1为所有磷流的计算公式,Sheet2为计算公式中所用到的原始数据的数值及其不确定度,Sheet3为物质流计算结果及不确定性分析,数据的单位均为kt P/yr。数据库中每列的含义可在正文中找到。
在《README.doc》中我们除了详细介绍了计算过程和数据来源,还展示并分析了部分关键结果,以下图为例
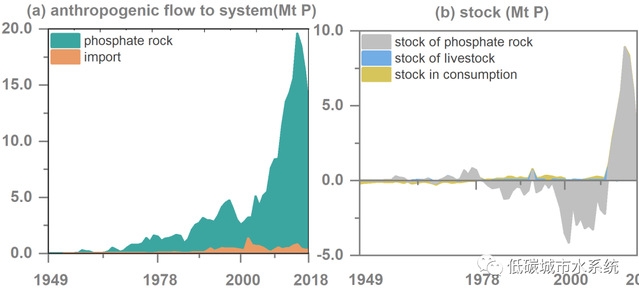

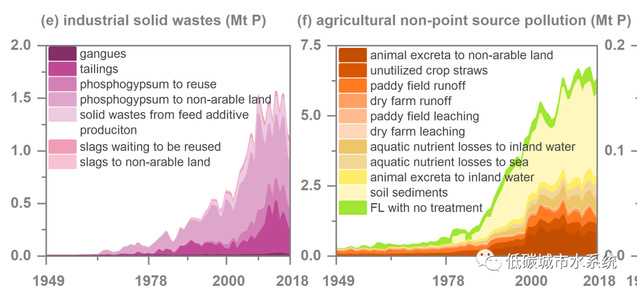
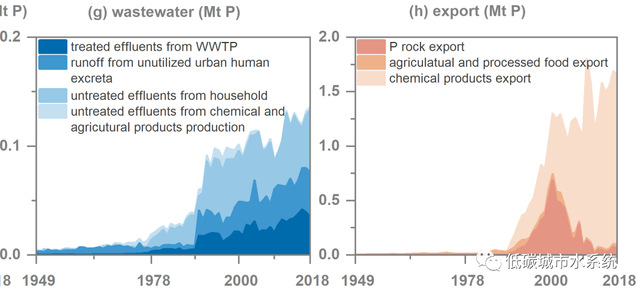
图 1949~2018年中国各磷流的质量变化。(a-d)为摇篮、存量、自然转移和废物中磷流量的质量变化情况。废物中磷流的质量变化分别由工业固体废物(e)、农业面源污染(f)、废水(g)、出口(h),以及其他固体废弃物组成.
Q5
可以提供一些利用这一数据的场景吗?
首先可利用此数据研究磷代谢的某些议题,比如饮食习惯、畜禽养殖与磷污染排放的关系、食物浪费中的直接磷损失与间接磷损失等;也可以用与辅助其他方法完善磷系统可持续性的评估,比如系统韧性分析、信息熵分析、生命周期评价等。也期待不同领域的研究者挖掘数据库更广泛的应用场景。
Q6
如果我利用了这一数据库,如何引用呢?Miao J, Wang X, Abulimiti A et al. Substance flow data of Chinese phosphorus cycle from 1949 to 2018[J]. Resources, Conservation and Recycling. 2023, 198: 107193. https://doi.org/10.1016/j.resconrec.2023.107193
作/者/信/息
Author Information
/ 第一作者/
苗静雨,2018级博士研究生,哈尔滨工业大学环境学院,主要从事磷物质流分析和信息熵分析的研究。
/ 通讯作者/
王秀蘅,哈尔滨工业大学教授,博士生导师。

版权所有©哈尔滨工业大学城乡水资源与水环境全国重点实验室 地址:哈尔滨市南岗区黄河路73号邮编:150090 电话:+86-451-86283787 邮箱:uwre@hit.edu.cn